
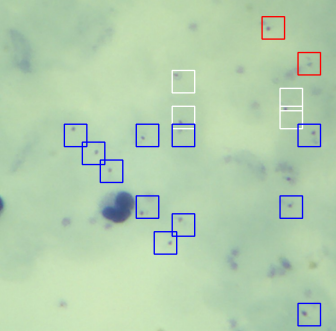
Malaria Parasite Detection
Accurate malaria diagnosis is critical, yet traditional microscopic analysis and rapid diagnostic tests have limitations, especially in regions with limited resources. In this project, funded by Grand Challenges Canada, we developed an automated diagnosis system using computer vision and image processing techniques. By analyzing blood smear images captured through standard microscopes, our approach compensates for the shortage of human expertise and enhances diagnostic accuracy, potentially reducing false positives and negatives. Learn More
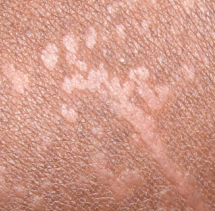
Tropical Skin Diseases Classification
Skin diseases are prevalent in sub-Saharan Africa, exacerbated by climate and limited access to trained medical personnel. Rural healthcare providers often rely on experience, leading to generalized treatments. In this project, funded by NUFFIC, we developed an image-processing method to classify skin disorders, distinguishing between viral and bacterial infections. With minimal training data, our approach demonstrates high accuracy, offering a valuable diagnostic tool in resource-limited settings. Learn More

Classification of Landsat 8 Images for Land use
Monitoring the impact of wars and conflicts on the environment and infrastructure is challenging, especially in dangerous areas like Somalia. This project uses Landsat 8 satellite imagery to classify land use and assess the environmental effects of forced displacement due to violent conflict. Focusing on regions like Banadir, where conflict and drought have caused significant displacement, the study quantifies the pressure on land use caused by the influx of internally displaced persons. The project demonstrates the effectiveness of using satellite imagery and shapefiles from OpenStreetMaps to analyze these impacts, highlighting potential for further study in other regions and improved labeling techniques. Learn More

Gender Identification from SMS Texts
This project addresses the challenge of identifying gender from SMS texts, motivated by UNICEF’s need to accurately target gender-specific campaigns on a youth crowd platform. With less than 40% of users providing gender information, and cultural sensitivities making it crucial to direct campaigns appropriately, we explored feature engineering focused on natural language processing (NLP) to capture differences in texting patterns between males and females. Machine learning models were then employed to predict gender, enabling UNICEF to tailor their outreach efforts effectively while avoiding potential cultural offenses.

Modeling Employee Flexible Work Scheduling as A Classification Problem
The COVID-19 pandemic prompted many organizations to adopt flexible working arrangements, revealing limitations in traditional employee scheduling methods, which are often optimized for compressed schedules. This research introduces a machine learning approach to transform employee scheduling into a classification problem by mining user-defined and soft constraints. By automatically extracting employee availability from personal calendars, the approach generates schedules through a multi-label classification method. Applied to university faculty scheduling, the method achieved a 93.1% accuracy in satisfying constraints, surpassing the 92.7% accuracy of traditional constraint programming methods. Learn More

Comprehensive Feature Engineering for Spam Detection
With nearly 59% of global emails being spam, the need for effective spam filtering has never been more critical, especially given the increasing presence of malware. Traditional spam detection methods are struggling to keep up with the rapid evolution of spam. In this project, we developed an automated feature engineering framework that significantly enhances spam classification by generating and transforming features from any email corpus. Our approach improves classification accuracy by 2% to 28% across various machine learning models. Additionally, we created a Python-based open-source tool that incorporates this framework. This project was funded by Higher Colleges of Technology, UAE. Learn More.

Detecting Bot Twitter Followers in a Real Industry Settings
This project addresses the challenge of identifying spamming accounts on social media platforms, specifically focusing on Twitter, where spammers degrade engagement and skew content perception. Using a large dataset, we developed a high-precision classifier that achieved an 87% detection rate with a 10% false positive rate, accurately identifying over 90% of spammers with fewer than three tweets. Recognizing the limitations of academic classifiers in real-world settings, we implemented a two-step filtering process to reduce false positives. Our approach successfully detected and disabled thousands of fraudulent accounts, with 95% being removed with Twitter’s assistance.

Mixed Language SMS Text Topic Modeling
Language identification in social media is challenging due to code-switching, lexical borrowings, and phonetic typing, making it necessary to detect language boundaries at the word level. This study focuses on mixed English SMS text corpora, introducing a code-mixing index to evaluate language blending. We investigate the use of Latent Dirichlet Allocation (LDA) for topic modeling in short SMS texts, particularly in crowd-sourced data used by international agencies like UNICEF for civic engagement and crisis response. Our findings reveal that conventional LDA models may struggle with short texts, leading us to develop a dictionary-based approach to accurately categorize topics. Additionally, we address polling biases in topic engagement, creating a model that distinguishes between the most important topics and those most frequently discussed.
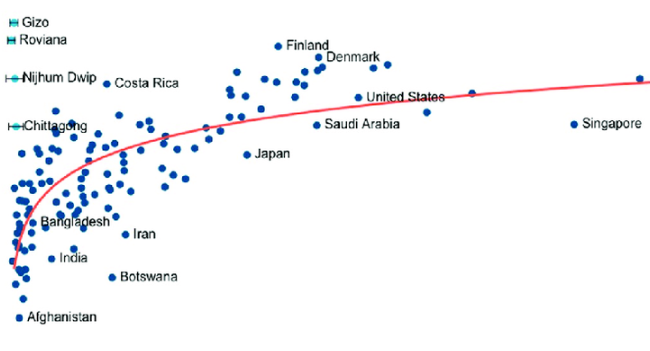
Predicting GDP Per Capita By Data Blending of Micro and Macro Economic Indicators
Accurately predicting GDP per capita is crucial for assessing a country’s economic performance and informing policy decisions. This study explores the potential of combining World Bank and IMF indicators to enhance GDP per capita predictions. Using random forest regressors, we demonstrate that blending these datasets achieves a higher predictive accuracy, with an R-squared of 0.79. Our analysis reveals that secure internet servers are the most significant predictor, contributing up to 60% relative importance. Additionally, for countries with GDP per capita below $50,000, net portfolio investment emerges as the most critical factor. This approach provides a more comprehensive understanding of economic conditions and improves prediction accuracy.

Alternative Data and Comprehensive Feature Engineering Short Term Financial Trading Strategy
This project tackles the challenge of accurately predicting stock market movements by leveraging modern machine learning techniques, particularly focusing on the estimation of stock price movements as local extrema. By combining comprehensive feature engineering from raw stock data with sentiment analysis, the study classifies stock movements into three states: sell, buy, or hold. The approach achieves a high F-score of 99.7% on minority classes using Extreme Gradient Boosting, outperforming sequential LSTM models on smaller datasets. This method demonstrates a significant improvement in short-term financial trading strategies.
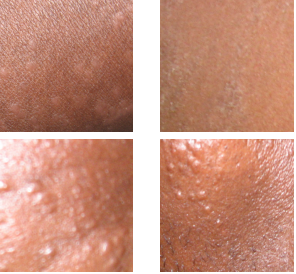
Exploring Classification of Bacterial and Viral Skin Diseases
Skin diseases are a major health concern in sub-Saharan Africa, with a prevalence of up to 34% and contributing significantly to outpatient visits. The shortage of dermatologists and reliance on visual diagnosis often leads to misdiagnosis and unnecessary treatments. This project addresses the challenge of accurate skin disease diagnosis by using machine learning techniques on a small dataset of skin images. Despite limited data, a CNN model achieved a 70% accuracy on the test set. Pre-trained models with feature extraction allowed for the successful training of Random Forest and Support Vector classifiers, matching CNN performance with lower training times. Additionally, agglomerative clustering produced higher-quality classifications, while k-means clustering provided better partitioning. These methods offer a promising approach to improving skin disease diagnosis in resource-limited settings. Learn More
Statistical Experimental Design: Impact of Prepaid Metering on Energy Consumption in Uganda
: In Uganda, the traditional postpaid electricity billing system leads to disconnections and revenue loss when customers are unable to pay their monthly bills. This study explores the adoption of prepaid metering as a solution, where customers purchase electricity upfront, potentially reducing energy waste and alleviating demand pressure on the national grid. With only 42.1% of Ugandans having access to electricity, this approach could extend service to more consumers without requiring new, environmentally damaging hydroelectric projects. The study aims to provide evidence on how prepaid metering can significantly reduce energy consumption in a developing country context.
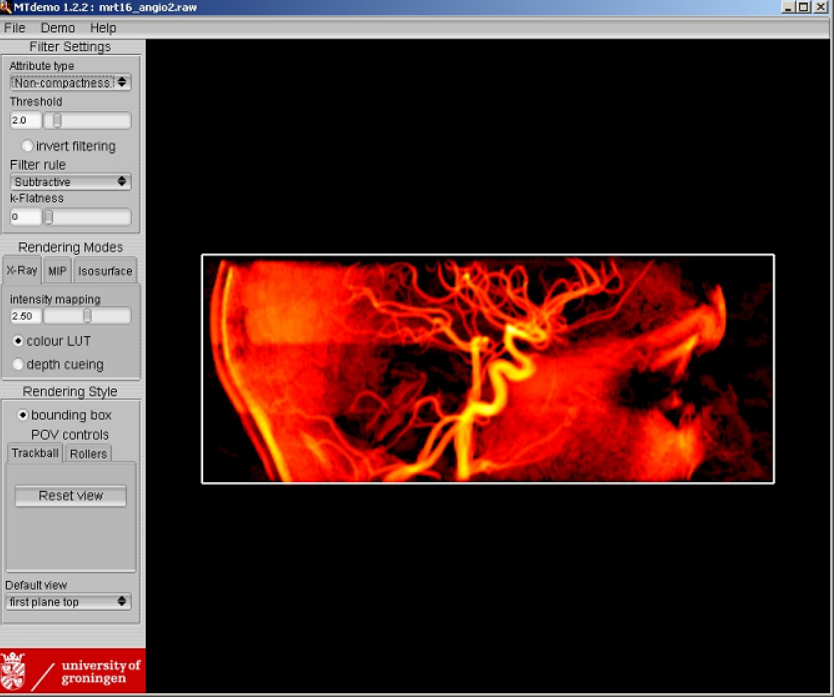
- Attribute Cluster Filtering for 3D Images (Chapter 5):
- Introduces a novel approach to 3D image filtering by replacing single attributes with attribute vectors for better discrimination of object classes.
- Describes an unsupervised pattern recognition method for selecting or rejecting objects based on feature vectors, offering flexibility and improved noise suppression. Demonstrates that this approach achieves better results than traditional scalar-attribute filtering, with reduced computational cost and simplified manual optimization.
This research presents both theoretical advancements and practical implementations, offering significant improvements in medical image analysis and contributing valuable tools for healthcare diagnostics.
Exploring morphological attribute filters in medical image enhancement
This thesis focuses on advancing morphological attribute filtering techniques for enhancing medical images, with key contributions in shape description, automatic threshold selection, and 3D attribute cluster filtering. The research addresses challenges in accurately characterizing and enhancing medical images, particularly in 3D imaging, through the development and implementation of novel methods. The work is organized into four main chapters, summarized as follows:
- Shape Descriptor for 3D Attribute Filtering (Chapter 2):
- Introduces a shape descriptor based on sphericity estimation for 3D objects, using an efficient algorithm to compute surface area and volume in a Max-tree structure.
- Demonstrates the application of this descriptor in detecting blood vessels, kidney stones, aneurysms, and lung nodules.
- Highlights the improved accuracy and rotation invariance compared to traditional methods.
- Radial-Moment Based Roundness Attribute (Chapter 3):
- Develops a new shape descriptor that is invariant to translation, rotation, and scaling, overcoming limitations of existing moment-based descriptors.
- Provides a memory-efficient algorithm for higher-order moment computation, enhancing robustness to noise in 3D medical images.
- Shows the effectiveness of this attribute in isolating kidney stones and other structures in CT and MRI images.
- Automatic Threshold Parameter Selection (Chapter 4):
- Proposes automated methods for threshold selection in attribute filtering, addressing the challenges of manual parameter tuning in medical image analysis.
- Explores techniques based on image segmentation, thresholding, and clustering, tailored to different medical imaging modalities.
- Emphasizes the importance of accurate and reproducible enhancement methods for improving diagnostic accuracy.